
Introducing CycleDash 0.0.0
28 Jan 2015When iterating on a variant caller, it’s helpful to be able to rapidly identify the most interesting variants called and to visually inspect the evidence used by the caller to make each call. CycleDash is our variant call analysis application, used to inspect, query, compare, and export variant calls imported from VCF files.
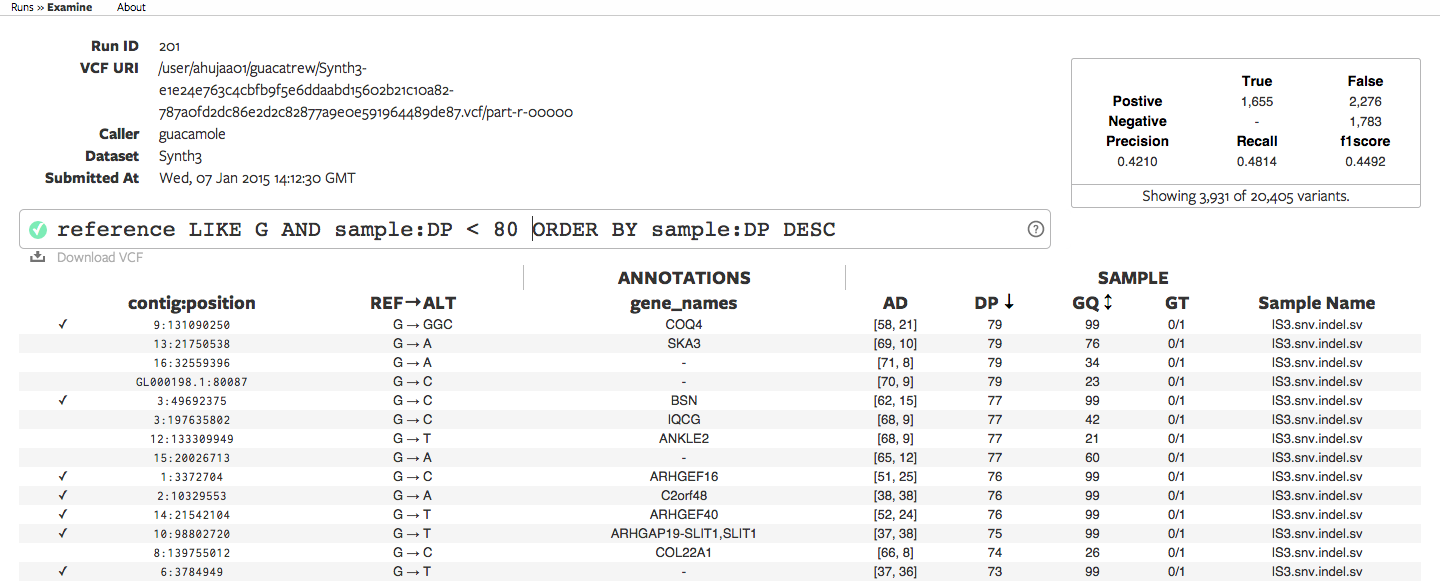
CycleDash displays variant calls in a tabular format. It provides summary statistics, annotations (e.g. the gene within which a variant occurs), a discussion/commenting system, and a powerful query omnibar which allows the user to quickly filter and sort the variants using an SQL-inspired syntax. It allows users to export the filtered variants as a VCF file for further downstream analysis.
Users can manually upload a VCF file to CycleDash through the web interface or they can point CycleDash to a VCF file stored on HDFS. When a VCF is submitted through either method, a request to process the VCF is placed on a work queue. Once processing is complete, the processed data is inserted into a PostgreSQL database in a denormalized format. The variants are then available for inspection through the web interface.
What’s in 0.0.0?
- A RESTful JSON API for submitting and querying VCFs.
- A dashboard listing all submitted VCFs + metadata.
- An “Examine” page for filtering and exploring the variants in a VCF, including
- A SQL-like query language for filtering and sorting variants.
- Download functionality for saving queried variants.
- An embedded pileup viewer for viewing variants in context.
- Summary statistics compared to a validation VCF, e.g. precision, recall, and F1 score.
- Workers for processing and annotating VCFs.
- A comment system for discussing variants.
What Are We Doing With It?
We’ve primarily used CycleDash to debug and improve Guacamole, our somatic variant caller. Ketrew posts the results of a run of Guacamole (or any other variant caller) to CycleDash, which in turn processes and imports the variant calls into PostgreSQL, where they are stored for later inspection.
In the future, we would like to use CycleDash to explore the functional consequences of variants. Exploring, discussing, and analyzing the results of a variant calling pipeline is often done in a series of Excel spreadsheets, written notes, and static images. When mature, CycleDash may be an improvement on existing workflows.
Current Limitations
Performance
CycleDash currently has trouble querying and serving call sets with over a million variants. We hope to improve performance for large call sets by optimizing our SQL queries. If we are not able to obtain the desired performance with PostgreSQL, we are open to exploring other databases. It’s a priority that CycleDash be responsive for even the most complex queries over the largest call sets.
Queryability
Our query engine cannot yet execute queries like “find all true positives”, “show all indels”, and doesn’t yet support queries over annotations or comments. We are also planning to support aggregate queries, user-defined functions, and saved queries.
Robust Error Handling
CycleDash fails in odd ways when it gets malformed and unexpected input. This is very confusing for users, and often involves diving into logs to figure out how something went wrong. Better error reporting is part of our ongoing goal to offer a seamless and pleasant UX to developers and non-technical users alike.
Roadmap
Some other highlights of our roadmap include the following:
- Comparison and concordance between different call sets.
- Introducing histograms and other visualizations and statistics.
- More annotation options and better pluggability for adding new annotations.
- A new, more performant, and purpose-built pileup viewer, pileup.js.
- Links between variants in CycleDash and the UCSC Genome Browser.
You can track (and add to) the project’s issues & features on GitHub Issues.